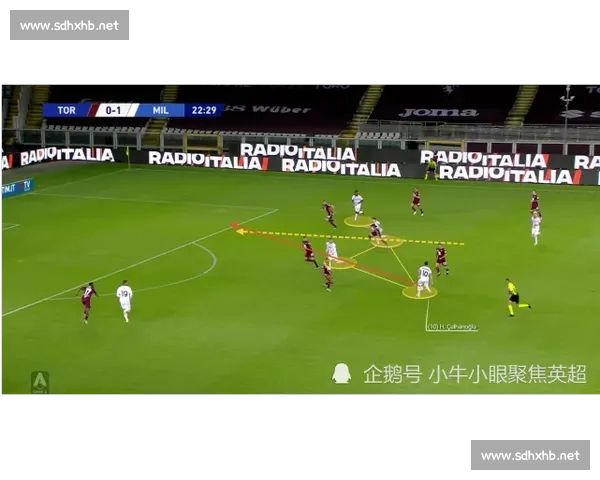
在当今竞技体育与各类竞赛环境中,比赛胜负早已不再仅由单一因素决定,而是多维数据共同作用的复杂结果。本文围绕“多维数据驱动下基于关键影响因素的比赛胜负结果分析与策略优化研究路径”展开系统探讨,从数据采集与整合、关键因素识别、模型构建与结果预测、策略优化与动态调整四个方面进行深入分析。通过多源数据融合与智能分析方法,可以有效揭示影响比赛结果的核心变量,并在此基础上建立科学决策模型,实现对比赛走势的精准预判。同时,借助实时反馈机制与策略迭代优化,不仅能够提升团队整体竞技水平,还可增强应对复杂局势的能力。本文旨在构建一条系统化、可实践的研究路径,为体育竞技、电子竞技乃至商业竞争等领域提供理论支持与实践参考。
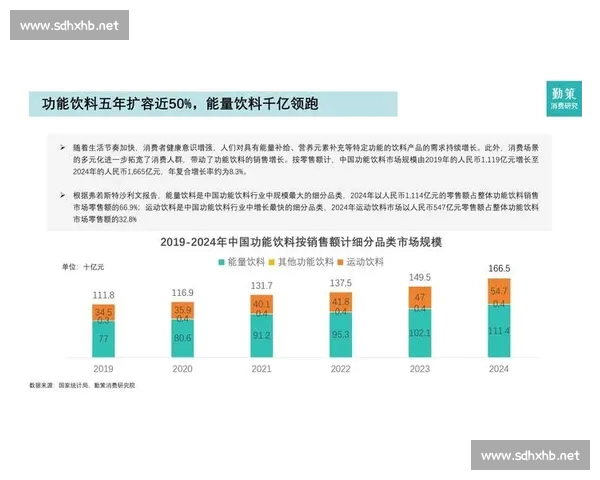
ng大舞台有梦你就来,Ng28大舞台有梦你就来,Ng28大舞台有梦你就来,ng大舞台有梦你就来多维数据驱动分析的基础在于全面而精准的数据采集。比赛相关数据不仅包括传统的技术统计数据,如得分、失误、控球率等,还涵盖运动员生理指标、心理状态、环境因素以及对手行为特征等。这些数据来源广泛,类型多样,需要借助传感设备、视频分析系统以及数据接口平台进行系统化收集。
在数据整合过程中,异构数据的标准化处理尤为关键。不同来源的数据往往存在格式差异、时间不同步以及精度不一致等问题,因此需要通过数据清洗、特征对齐与时间序列同步等技术手段进行预处理,从而构建统一的数据结构体系。
此外,多维数据整合还需关注数据质量与完整性。缺失数据填补、异常值检测以及数据冗余处理,都是确保后续分析准确性的关键步骤。通过构建高质量数据仓库,可以为模型分析提供坚实的数据支撑。
在海量数据中识别出真正影响比赛结果的关键因素,是实现有效分析的核心环节。通过统计分析方法,如相关性分析、主成分分析以及因子分析,可以初步筛选出与胜负结果高度相关的变量。
进一步地,可以引入机器学习算法,如随机森林、梯度提升树等,对特征重要性进行评估。这些方法能够从非线性关系中挖掘隐藏模式,从而识别出传统分析难以发现的关键变量。
与此同时,领域知识的融合也不可忽视。教练经验、战术理解以及比赛情境判断,能够帮助对数据分析结果进行合理解释,并避免“数据偏见”带来的误导。数据驱动与经验判断的结合,是提升因素识别准确性的有效路径。
在识别关键影响因素之后,需要构建相应的预测模型以分析比赛结果。常见模型包括逻辑回归、支持向量机以及深度神经网络等,这些模型能够根据历史数据学习胜负规律,并进行概率预测。
模型构建过程中,应注重训练集与测试集的合理划分,以避免过拟合现象。同时,通过交叉验证等方法,可以提升模型的泛化能力,使其在不同比赛环境下仍具备较高的预测准确性。
此外,模型解释性同样重要。通过SHAP值或LIME等解释方法,可以揭示模型决策过程,使分析结果更具透明性。这不仅有助于优化模型结构,也为策略制定提供了明确依据。
基于预测模型的输出结果,可以进一步制定比赛策略。例如,在识别出关键得分区域或对手薄弱环节后,可针对性地调整进攻或防守策略,从而提高获胜概率。
在实际比赛过程中,策略需要具备动态调整能力。借助实时数据反馈系统,可以对比赛进程进行持续监控,并根据实时变化对策略进行修正。这种“边预测边调整”的模式,使策略更具灵活性与适应性。
同时,策略优化还应考虑长期发展。通过对多场比赛数据的持续分析,可以不断修正模型参数与策略体系,实现从短期胜利到长期竞争力提升的转变,形成闭环优化机制。
总结:
综上所述,多维数据驱动下的比赛胜负分析,不仅是一种技术手段,更是一种系统化思维方式。通过数据采集、因素识别、模型构建与策略优化的有机结合,可以全面提升对比赛本质的理解,实现从经验决策向科学决策的转变。
未来,随着人工智能与大数据技术的不断发展,该研究路径将进一步深化与拓展。在更多领域中,这一方法将展现出更强的应用价值,为复杂决策问题提供更加精准、高效的解决方案。
北京市西城区金融大街甲17号首层